Java - Multi Thread에서 동시성 제어
업데이트:
서비스 Application에서 멀티 스레드를 다루는 일은 필수 일 것입니다.
저도 멀티 스레드를 다루는 방법에 대해 다시 한번 복기 및 몰랐던 것을 더 알고자 이번 포스트를 작성하게 되었습니다.
이번 포스트는 DevEric님의 포스트를 참고하여 작성하였습니다.
[Java] Multi Thread환경에서 동시성 제어를 하는 방법
스레드와 프로세스는 알고계신다는 전제하에 작성한 포스트입니다. 스레드와 프로세스는 다른 블로그들 찾아보시면 좋은 글들이 많으니 먼저 학습하신 뒤에 제 포스트를 보시는 편이 이해하시는데 도움되실겁니다~😄
멀티 스레드 예시 코드
다음 코드를 보겠습니다.
public class Application {
public static void main(String[] args) {
implicitLock();
}
private static void implicitLock() {
Count count = new Count();
int index = 100;
Runnable task = new Runnable() {
@Override
public void run() {
for (int j = 0; j < index; j++) {
count.view();
}
}
};
for (int i = 0; i < index; i++) {
Thread thread = new Thread(task);
thread.start();
}
}
}
class Count {
private int count = 1;
public int view() {
System.out.println("Thread = " + Thread.currentThread() + ", count = " + count++);
return count;
}
public int getCount() {
return count;
}
}
100개의 스레드에서 각각 100번 count.view() 호출이 일어난 코드입니다.
view() 메소드는 count 변수를 증가 시키고 있습니다.
최종 호출은 100 * 100 = 10,000이 출력됨을 예상할 수 있습니다.
하지만 결과는??
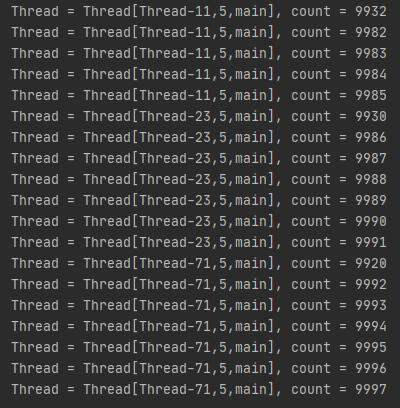
9997이 나오며 예상했던 결과와 다른 결과가 나온 것을 확인할 수 있습니다.
이유가 뭘까요?
자원의 공유
스레드는 다양한 자원을 공유하는데 그 중 하나가 Heap에 있는 자원을 공유하는 것입니다.
new 키워드로 생성한 객체는 Heap에 생성됩니다.
따라서, 위의 코드에서 new Count()로 생성한 count는 여러 스레드에서 공유하게 됩니다.
동시 접근 (=동시성 이슈)
시나리오를 생각해보겠습니다.
임의의 상태에서 count가 100일 때 Thread1과 Thread2가 동시에 count에 접근합니다.
Thread1은 100 → 101로 증가시킵니다.- 그런데
Thread2에서도count에 접근하여 100 → 101로 증가시킵니다.
count.view()가 2번 호출됐으므로 100 → 101 → 102가 되어야 하지만 각각의 스레드가 공유 자원인 count에 동시에 접근했기 때문에 결과는 101이 됨을 알 수 있습니다. 이런 현상이 무작위로 발생했기 때문에 9997이라는 최종 결과값이 나오게 된 것입니다.
(count 값의 변화를 보시면 일정하게 순차적으로 증가하는 것이 아니라 중구난방으로 증가하는 것을 볼 수 있습니다.)
분명 이런 상황은 개발자가 의도한 상황은 아닐겁니다.
그럼 이런 동시 접근 상황을 해결하는 방법은 무엇이 있을까요?
동시성을 제어하는 방법
암시적 Lock
❓Lock이란? Lock은 한 스레드가 자원을 사용하면 다른 스레드에서 접근하지 못하도록 막는 것입니다.
가장 쉬운 방법은 Lock을 걸어 버리는 겁니다. 한 번에 하나의 스레드만 접근하고 다른 스레드는 대기 상태에 있게 됩니다.
하지만 이런 Lock 방법은 한 번에 하나의 스레드만 처리하기 때문에 성능이 많이 저하가 됩니다.
그리고 이런 Lock을 걸수 있는 방법으로 Java의 키워드인 synchronized를 사용하면 됩니다.
synchronized은 메소드와 변수에 걸 수 있습니다.
메소드 synchronized
class Count {
private int count = 0;
public synchronized int view() {
return count++;
}
}
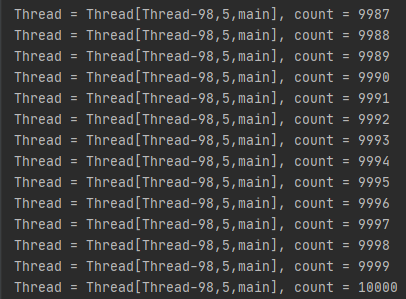
결과를 보면 정상적으로 10,000이 출력되고 count도 순차적으로 증가하는 것을 확인할 수 있습니다.
즉, 하나의 스레드가 count를 증가 시킬 때 다른 스레드는 접근하지 못했다는 뜻입니다.
(정확히는 view() 메소드에 접근하지 못한 것입니다.)
변수 synchronized
💡변수
synchronized을 사용하기 위해서 해당 변수는 반드시 객체여야 합니다.int,long같은 primitive type은 변수synchronized을 사용할 수 없습니다.
class Count {
private Integer count = 0;
public int view() {
synchronized (this.count) {
return count++;
}
}
}
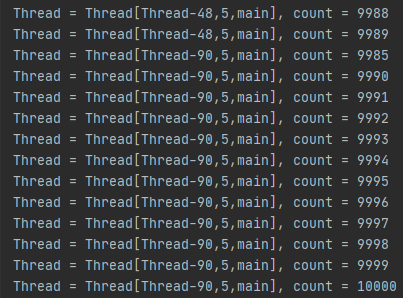
결과를 보시면 10,000이 출력됩니다. 하지만 count는 순차적으로 증가하지 않았음을 알 수 있는데요.
view() 메소드는 Lock이 걸려있지 않기 때문에 어느 스레드에서나 접근하지만 count에는 접근하지 못하기 때문입니다.
명시적 Lock
명시적 Lock이란 synchronized 키워드 대신 ReentrantLock을 사용하는 Lock을 명시적 Lock이라고 합니다.
Lock의 범위를 메소드나 변수로 설정하는 것이 아니라 개발자의 뜻대로 Lock을 사용하고 싶을 때 사용합니다.
사용법은 ReentrantLock으로 생성한 Lock 객체의 lock() 메소드로 시작, unlock() 메소드로 Lock을 해제 합니다.
다음은 Count 클래스에서 멤버 변수로 ReentrantLock() 메소드를 추가한 코드입니다.
class Count {
private int count = 1;
private Lock lock = new ReentrantLock();
public synchronized int view() {
System.out.println("Thread = " + Thread.currentThread() + ", count = " + count++);
return count;
}
public Lock getLock() {
return lock;
}
}
다음은 명시적 Lock을 사용한 코드입니다.
private static void explicitLock() {
Count count = new Count();
int index = 100;
Runnable task = new Runnable() {
@Override
public void run() {
for (int j = 0; j < index; j++) {
count.getLock().lock();
count.view();
count.getLock().unlock();
}
}
};
}
위 코드에서 count.getLock().lock() 부분부터 count.getLock().unlock()시점 까지 다른 스레드에서 접근하지 못하도록 Lock을 겁니다.
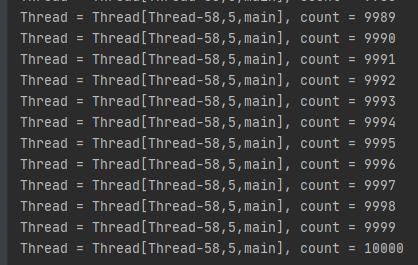
위 코드에서 synchronized 와 마찬가지로 view() 메소드에 Lock을 건 것과 마찬가지 이기 때문에 순차적으로 count가 증가하는 것을 알 수 있습니다.
volatile
❓volatile이란? 변수의 값을 매번 CPU Cache가 아닌 Main Memory에서 읽는 것을 명시해주는 것입니다.
Multi Thread 환경에서 각각의 스레드는 성능 향상을 위해 CPU Cache라는 공간에 값을 저장하는데 각각의 스레드 공간이 다르기 때문에 변수 값의 불일치 문제가 발생하게 됩니다.
변수에 volatile 키워드를 추가하여 Main Memory에 저장/읽기를 하도록 명시해줘서 변수 값 불일치 문제를 해결할 수 있습니다.
사용처
여러 스레드에서 쓰기(Write)하는 상황이면 volatile 보다는 synchronized를 사용하는 것이 옳습니다.
volatile은 여러 스레드에서 접근하면 덮어쓰기가 될 소지가 있습니다.
💡지금까지 위에서 말했던 상황과 동일한 상황인데 Main Memory에 존재하는 공유되 자원(=변수)에 접근하여 Lock 없이 “쓰기”가 되어버리기 때문입니다.
따라서 volatile은 하나의 스레드만 쓰기(Write)를 하고 나머지 스레드는 읽기(Read)만 하는 상황에 적합합니다.
Thread-Safe 객체 사용
Java에서는 이미 멀티 스레드에서 Thread-Safe하게 만들어 놓은 패키지 및 클래스들이 있습니다.
이것들은 일반적인 synchronized와 Lock을 사용해야 하는 상황에서 최대한 성능을 내도록 최적화되어있기 때문에 이들을 적극적으로 활용하도록 합시다.
Concurrent 패키지
다음은 java.util.concurrent.atomic 패키지 안에 있는 AtomicInteger 클래스를 이용한 코드입니다.
AtomicInteger의 getAndIncrement() 메소드를 이용하여 위의 count++ 부분을 Thread-Safe하게 동작하도록 하였습니다.
class ConcurrentCount {
private AtomicInteger count = new AtomicInteger(1);
public int view() {
int increment = count.getAndIncrement();
System.out.println("Thread = " + Thread.currentThread() + ", count = " + increment);
return increment;
}
}
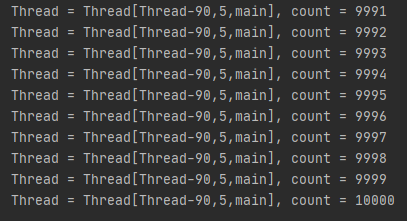
결과는 다음과 같이 10,000이 정상으로 출력되는것을 확인할 수 있습니다.
ConcurrentHashMap
concurrent 패키지에서 제일 잘 알려지고 사용하는 클래스는 ConcurrentHashMap이 아닐까 싶습니다.
예전에는 Map 콜렉션에서 멀티 스레드에서 안정적으로 사용하려면 put(), get() 같은 메소드에 synchronized 키워드가 추가되어있는 HashTable을 사용했었습니다. 하지만 Java 8에서 ConcurrentHashMap이 나오면서 이를 대체하게 되었습니다.
Lock을 여러개로 분할하여 사용하는 Lock Striping 기법을 사용하여 성능과 병렬성을 모두 잡았습니다.
내부 구조까지는 저도 잘 모르겠습니다만 앞으로 멀티 스레드에서 Thread-Safe하게 Map을 사용할 일이 있으면 ConcurrentHashMap을 사용하시면 됩니다.
불변 객체
❓불변객체란? 객체가 한 번 생성되면 그 상태값이 변하지 않는 객체를 불변 객체라고 합니다.
멀티 스레드 환경에서 Thread-Safe한 프로그래밍 방법 중 하나로 불변 객체를 만드는 것이 있습니다.
불변 객체를 만드는 방법은 여러가지가 있습니다. 불변 객체는 공유 자원이 아닌 매번 새로운 객체를 Heap 영역에 생성하여 스레드에서 사용하기 때문에 동시성 이슈가 발생할 일이 없고 Lock로 필요없기 때문에 성능상 이슈도 없습니다.
💡성능상 이슈가 없다는 말은 정확히 표현하자면 잘못된 표현 같네요. Heap 영역에 계속해서 새로운 객체, 즉 메모리가 사용되는 만큼 기존 사용했던 객체의 메모리 해제가 제대로 이루어지지 않는다면 메모리 사용적인 측면에서 성능 이슈가 발생하게 될 것입니다.
하지만 G1 GC가 나왔을 정도로 가비지 컬렉터의 성능이 좋아졌기 때문에 왠만하면 메모리 부족에 대한 이슈는 발생하지 않을까 싶습니다.
그중 제가 아는 방법 몇 가지를 소개해드리면
- 멤버 변수를
private,final로 선언 - 객체 생성자를
private으로 하고 Factory 메소드를 사용 - Setter를 사용하지 않는 것.
이 있습니다.
마무리
오늘은 멀티 스레드 환경에서 동시성 이슈 및 제어하는 방법에 대해서 알아봤습니다.
보통 저처럼 Spring을 사용하시는 분들은 멀티 스레드 환경으로부터 도움을 받아 크게 신경쓸일은 없을지도 모르겠지만
(Spring은 스레드 풀과 nio connector를 사용하여 멀티 스레드의 환경을 구동하는 것으로 알고 있는데 이 부분은 저도 추가로 학습해야돼서 다음에 포스트를 작성해보겠습니다.)
반드시 마주칠 상황이 오기 때문에 꼭 알고 있어야 한다고 생각합니다.
특히 불변 객체는 이제 습관적으로 사용하는 것이 좋다고 생각하고 있습니다만 저도 아직 숙련도가 부족해서 숙련도를 끌어올려야 겠습니다. 😅오
오늘은 포스트가 유독 길었는데요.
긴 포스트를 보시느라 수고 하셨습니다.
항상 감사합니다😀
댓글남기기