Stream (3) - 자주 사용하는 메소드(최종 연산 메소드)
업데이트:
이전 포스트에서 Stream의 중간 연산 메소드에 대해 알아봤습니다.
이번에는 자주 사용하는 Stream 마지막편 최종 연산 메소드에 대해 알아보겠습니다.
최종 연산 메소드
이전 중간 연산 메소드는 반환 시 Stream을 반환합니다.
예시로 filter() 메소드를 보면 Stream<T>가 반환되는 것을 확인할 수 있습니다.
Stream<T> filter(Predicate<? super T> predicate);
즉, 연속해서 다음 메소드를 사용할 수 있다는 것입니다.
반면에 최종 연산 메소드는 Stream이 아닌 다른 메소드에 특성에 맞춰 다른 반환 타입을 가집니다.
어려울 것 없이 Stream이 종료되는 메소드인 것이죠.
주의할 점은 최종 연산 메소드 이후에는 동일한 Stream을 재사용할 수 없다는 것을 기억해주시면 됩니다.
forEach()
중간 연산 메소드인 peek()과 마찬가지로 반환하지 않는(void)인 작업을 하는 메소드입니다.
다른 점은 peek()은 최종 연산자가 있어야만 실행되고 forEach()는 그 자체가 최종 연산자이기 때문에 단독으로 사용가능한 것입니다.
@Test
void forEach() {
List<String> players = List.of("jordan", "kobe", "iverson", "wade", "curry");
players.stream()
.forEach(System.out::println);
}
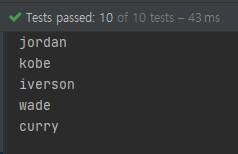
결과를 보면 모두 출력된 것을 확인할 수 있습니다.
count()
count()는 이름에서 알 수 있듯이 Stream 내부 요소의 개수를 알려주는 메소드입니다.
@Test
void count() {
List<String> players = List.of("jordan", "kobe", "iverson", "wade", "curry");
long count = players.stream()
.count();
System.out.println("count = " + count);
}
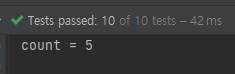
예상들 하시겠지만 Stream의 전체 요소가 아닌 중간 연산 메소드 있을 경우 중간 메소드를 실행하고 최종 Stream의 요소 갯수를 반환합니다.
다음은 이름의 길이가 4이상인 조건(filter)를 추가한뒤 count()를 호출하는 코드입니다.
@Test
void filter_count() {
List<String> players = List.of("jordan", "kobe", "iverson", "wade", "curry");
long count = players.stream()
.filter(name -> name.length() > 4)
.count();
System.out.println("count = " + count);
}
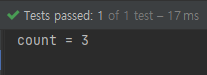
findFirst()
findFirst()는 요소 중 첫 번째 요소를 반환하는 메소드입니다.
물론 이것도 중간 메소드 실행 후 최종 Stream의 요소 중 첫 번째 요소를 반환합니다.
@Test
void findFirst() {
List<String> players = List.of("jordan", "kobe", "iverson", "wade", "curry");
Optional<String> first = players.stream()
.findFirst();
System.out.println("first = " + first);
}
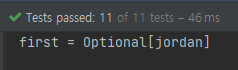
단지 특이한 점이라면 요소 타입을 그대로 반환하는 것이 아니라 Optional로 감싸서 반환하는 것을 확인할 수 있습니다.
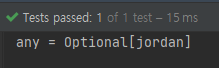
findAny()
findAny() 메소드도 findFirst()와 동일한 요소를 그것도 Optional까지 똑같이 반환합니다.
@Test
void findAny() {
List<String> players = List.of("jordan", "kobe", "iverson", "wade", "curry");
Optional<String> any = players.stream()
.findAny();
System.out.println("any = " + any);
}
그럼 둘의 차이점을 무엇일까요?
Stream을 병렬로 처리할 시 둘의 차이점을 확인할 수 있습니다.
💡Stream은 병렬 처리를 위해 중간 연산 메소드로
parallel()를 제공합니다.
여러 Thread에서 하나의 Stream에 접근하여 필터링을 거칠때, findFirst()는 원래 Stream의 순서를 고려하여 가장 앞에 있는 요소를 반환하는 반면, findAny()는 필터링에 부합하는 요소를 Stream의 순서와 상관없이 먼저 찾아지는 것을 반환합니다.
백문이불여일견
예제 코드를 봐보겠습니다.
@Test
void differentFind() {
List<String> findFirstStream = List.of("jordan", "kobe", "iverson", "wade", "curry");
Optional<String> first = findFirstStream.stream()
.parallel()
.findFirst();
System.out.println("first = " + first);
List<String> findAnyStream = List.of("jordan", "kobe", "iverson", "wade", "curry");
Optional<String> any = findAnyStream.stream()
.parallel()
.findAny();
System.out.println("any = " + any);
}
위의 코드를 여러 실행해보겠습니다.
예상으론 first는 계속해서 Optional[jordan]이 출력될 것이고, any는 먼저 찾아지는 것을 출력하기 때문에 어떤 것이 먼저 나올지 예측할 수 없습니다.
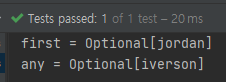
findFirst()는 Optional[jordan]을 findAny()는 Optional[iverson]을 출력했네요.
예상하셨을 수도 있지만 findFirst()의 경우에는 결과 값을 도출하고, 순서를 보장하기 위해 추가 비용이 듭니다. 반면에 findAny()는 조건에 맞는 요소를 찾는 즉시 메소드가 종료되기 때문에 비용적인 측면에서 이득이 있습니다.
목적에 따라 다르겠지만 병렬처리에서 firstFirst()는 순서가 보장되어 예측이 가능한 값 도출을 원할 때, findAny()는 예측 불가능하지만 비용 측면에서 이득을 보기 위해 사용하면 됩니다.
allMatch()
Matching 관련 Stream 메소드는 이름에서 바로 알 수 있듯이 직관적입니다. (다른 메소드도 마찬가지이긴 하지만요)
allMatch()는 Stream내의 모든 요소가 조건에 부합하는지를 판별해주는 메소드입니다.
@Test
void allMatch() {
List<String> players = List.of("jordan", "kobe", "iverson", "wade", "curry");
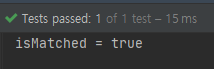
boolean isMatched = players.stream()
.allMatch(name -> name.length() > 5);
System.out.println("isMatched = " + isMatched);
}
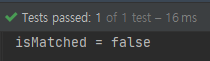
6글자 이상인 요소는 jordan, iverson 밖에 없기 때문에 모든 요소가 만족하지 못합니다. 따라서 false가 출력됩니다.
조건을 다음과 같이 3글자 이상으로 바꾸게 되면 true가 출력되는 것을 확인할 수 있습니다.
name -> name.length() > 3
anyMatch()
allMatch()와 달리 anyMatch()는 하나의 요소라도 조건을 만족하면 true, 만족하는 요소가 전혀 없으면 false를 출력합니다.
위와 동일한 로직에서 조건만 6글자 이상으로 바꿔보겠습니다.
name -> name.length() > 6
iverson만이 조건에 부합합니다.
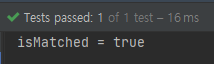
이번에는 조건을 7글자 이상으로 바꿔보겠습니다.
name -> name.length() > 7
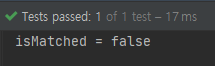
그럼 결과가 false로 출력되는 것을 확인할 수 있습니다.
noneMatch()
noneMatch()는 하나도 만족하는 요소가 없을때 true, 하나라도 있으면 false를 출력합니다.
anyMatch()와 완전 반대 개념으로 생각하시면 됩니다.
그래서 위의 코드를 동일하게 실행하고 결과를 보도록 하겠습니다.
name -> name.length() > 6
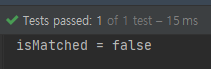
name -> name.length() > 7
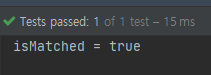
anyMatch()와 반대의 결과가 나오는 것을 확인할 수 있습니다.
reduce()
reduce()는 어떤 로직을 인자로 하여 하나의 결과를 도출해내는 메소드입니다.
(개인적으론 이해하는데 좀 어려웠던 메소드입니다. 메소드명이 한 몫한것 같습니다. ㅎㅎ)
코드를 보겠습니다.
@Test
void reduce() {
List<String> players = List.of("jordan", "kobe", "iverson", "wade", "curry");
OptionalInt reduce = players.stream()
.mapToInt(name -> name.length())
.reduce((a, b) -> a + b);
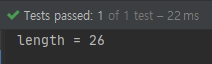
System.out.println("length = " + reduce.getAsInt());
}
Stream 요소들의 이름 길이의 총합을 구하는 코드 입니다.
결과는 26임을 확인할 수 있습니다.
reduce()는 총 가지 메소드가 오버로딩 되어있는데, 다음과 같습니다.
Optional<T> reduce(BinaryOperator<T> accumulator);
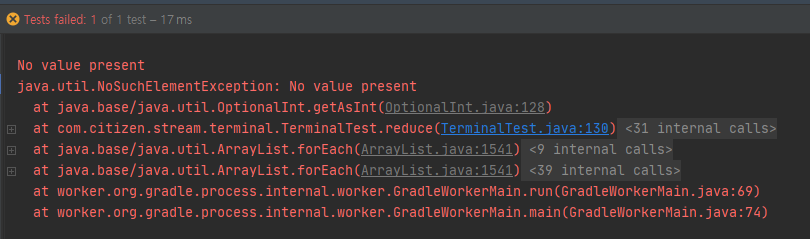
제가 위에서 사용했던 시그니처의 메소드입니다. 특별할 것은 없지만 한 가지 유의 할 점은 로직을 실행항 Stream이 비어있다면 NoSuchElementException가 발생하게 됩니다.
T reduce(T identity, BinaryOperator<T> accumulator);
identity는 초기 값으로 Stream이 비어있더라도 위 코드처럼 Exception이 발생하지 않습니다.
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
위의 코드와 다른 점을 발견할 수 있는데 바로 combiner입니다.
이 combiner이란 병렬 스트림에서 나워 계산한 결과를 하나로 합치는 로직을 말합니다. 즉, 병렬 스트림에서만 동작합니다. 저도 이해가 어렵기 때문에 바로 코드를 보겠습니다.
@Test
void parallel_reduce() {
Integer result = Arrays.asList(1, 2, 3, 4, 5)
.parallelStream()
.reduce(10,
Integer::sum,
(a, b) -> {
int i = a + b;
System.out.println("a = " + a);
System.out.println("b = " + b);
System.out.println("combiner 호츌 : " + i);
return i;
});
System.out.println("result = " + result);
}
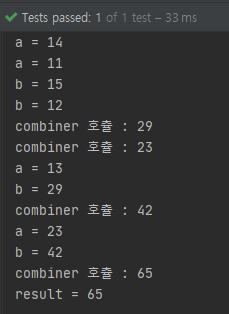
결과를 보면 65가 나왔습니다.
원래 단일 스트림이라면 10 + 1 + 2 + 3 + 4 + 5 = 25가 나와야 하는데 65는 어떻게 도출된걸까요?
개별 요소마다 초기값 10과 더하고 그 총 5개의 결과를 더한 값이 65가 되는 것입니다.
그리고 병렬 스트림이기 때문에 계산의 순서가 예측이 불가하기 때문에 중간 연산 순서는 중요하지 않습니다. 최종 결과값만 어떻게 될지를 예상하면 됩니다.
collect() - toList() 사용
collect() 메소드는 Stream의 요소를 다시 Collections로 변환시켜줍니다.
List<String> players = List.of("jordan", "kobe", "iverson", "wade", "curry");
List<String> collect = players.stream()
.collect(Collectors.toList());
System.out.println("collect = " + collect);

예제에서는 Collectors.toList()를 사용하였지만, toSet()도 있고 toMap()도 있으니 필요에 맞춰 사용하면 됩니다.
collect() - joining() 사용
collect() 내부에 Collectors.*joining*(" : ")을 사용하게 되면 요소를 특정 문자로 통합시켜줍니다. 예전에 for문을 돌며 String에 구분 문자를 붙이는 불편함을 대신한 메소드입니다.
@Test
void collect_joining() {
List<String> players = List.of("jordan", "kobe", "iverson", "wade", "curry");
String collect = players.stream()
.collect(Collectors.joining(" : "));
System.out.println("collect = " + collect);
}

마무리
오늘은 Stream에서 최종 연산 메소드를 알아보았습니다. 이 밖에도 다양한 메소드가 있지만 실무에서는 이정도만 알아도 Stream을 사용하는데 큰 무리가 없을 거라 생각합니다.
저도 이 모든 메소드를 자유자재로 사용하려면 아직 멀었다 생각합니다 ㅎㅎ
오늘도 제 포스트를 봐주셔서 감사합니다.😄
댓글남기기